-
크롤링할 일이 생겨서 급하게 만들었는데, 어떤 식으로 만들었는지 기록해두려고 작성합니다.
#개발과정
1. robots.txt 확인
2. 대상 페이지 확인
3. 디자인
4. 구현
---
#
1. robots.txt 확인
제일 먼저 크롤링하기전에 robots.txt를 확인합니다.
User-agent: * Disallow: /admin Disallow: /api Allow: /robots.txt가 어떻게 되어있는지에 따라서 크롤링 해도 되는것과 하면 안되는 것을 확인해야합니다.
사실 robots.txt에서 Allow라고 되어있다고 해서 무조건 해도 된다는 것은 아닙니다만, Disallow라고 되어있으면 절대 하면 안됩니다.
#
2. 대상 페이지 확인
Requirements 1. 상품 코드 2. 상품 이미지 3. 상품 상세페이지 4. 상품명 5. 판매가격 6. 옵션대상 페이지에서 가져오고자 한 정보는 위와 같았고, 이미지를 다운로드하는 것은 너무 오래걸리고 저장공간도 많이 필요로 하기에, 이미지 대신 이미지가 저장된 위치의 URL을 저장하고자 했습니다.
- 상품 코드
상품코드의 경우에는 상품 상세페이지의 링크에서 확인가능했습니다. 그래서 상세페이지를 파싱해서 상품 코드를 가져오고자 합니다.
- 상품 이미지
상품 이미지는 상품 상세페이지에서 이미지 표시해주는 부분을 확인했고, 그 이미지의 URL을 확인해서 가져오고자 했습니다.
- 상품 상세페이지
상품 상세페이지는 전체 상품 리스트 페이지에서, 각 상품명을 클릭했을때 이동하는 href를 파악해서 이를 이용했습니다.
- 상품명
상품명은 전체상품 리스트 페이지에서 나타나있었기에 이를 이용했습니다.
- 판매가격
판매가격은 조금 특이했는데, 로그인을 하지 않으면 가져올 수 없었기에 로그인을 한 후 가격정보를 파싱했어야 했습니다. 이후 전체상품리스트 페이지에서 가져오고자 했습니다.
- 옵션
옵션은 상품 상세페이지에서 옵션을 선택가능한 부분이 있었고, 이 부분에서 옵션을 가져왔습니다.
#
3. 디자인
사이트를 살펴보니, 크롤링 순서를 세 스텝으로 진행해야 겠다고 생각했습니다.
앞서 2번에서 대상 페이지와 Requirements를 보면, 전체 상품 리스트 페이지에서 데이터를 가져와야 하는 부분과 각 상품의 상세페이지에서 가져와야하는 부분이 있었습니다. 또한, 로그인을 필요로 하는 작업도 있었습니다.
그래서 다음과 같이 세 스텝을 정했습니다.
1단계: 로그인하여 세션을 유지한다.
2단계: 전체상품 리스트 페이지에서 **상품 상세페이지 URL, 상품명, 상품코드, 상품가격**을 가져옵니다.
3단계: 각 상품의 상세페이지에 접속해서 **이미지 URL, 옵션**을 가져옵니다.
그리고 마지막으로 진행상황을 보여주는 Progress 바를 만들어서 진행상황을 보고자했습니다.
이는 처음 디자인시에는 예정에 없던 것인데, 구현하다 보니 3단계에서 각 상세페이지에 접속해야했기에 시간이 조금 걸려서 필요를 느껴 만들어줬습니다.
#
4. 구현
구현할 때 셀레니움(selenium)을 사용하는 경우가 종종 있는데, 셀레니움은 최대한 사용하지 않는 것이 좋습니다. 이는 웹 브라우저를 실행하여 GUI를 구성해야하기 때문에, Reuqest로 html 텍스트만 받아와서 처리하는 것보다 훨씬 긴 시간이 걸립니다. 그래서 다른 방법으로 도저히 안 되는 경우에만 셀레니움을 사용해야합니다.
그래서 구현은 requests모듈과 BeautifulSoup 모듈을 사용해서 Python으로 구현했습니다.
0) request를 보낼 때 주의할 점
기본적으로 대부분의 사이트 구현 프레임워크들은 로봇이 접속하는 것을 막아두고 있습니다. 그래서 User-Agent를 지정해줘서 지금 request가 어떤 프로그램이 보내는 것이 아니라 브라우저가 보내는 것이라고 알려주어야만 차단되지 않습니다.
위와 같은 사이트에서 내가 브라우저를 통해서 request를 보낼 때 어떤 정보들이 기본적으로 헤더에 붙어있는지 확인해주고 적절하게 이를 붙여서 보내주어야 합니다.
가장 기본적으로는 User-Agent를 통해서 프로그램인지 판단하기에 이부분에 대한 정보만 request보낼때 기본적으로 헤더에 추가해줬습니다.
1) main함수는 다음과 같이 구현했습니다.
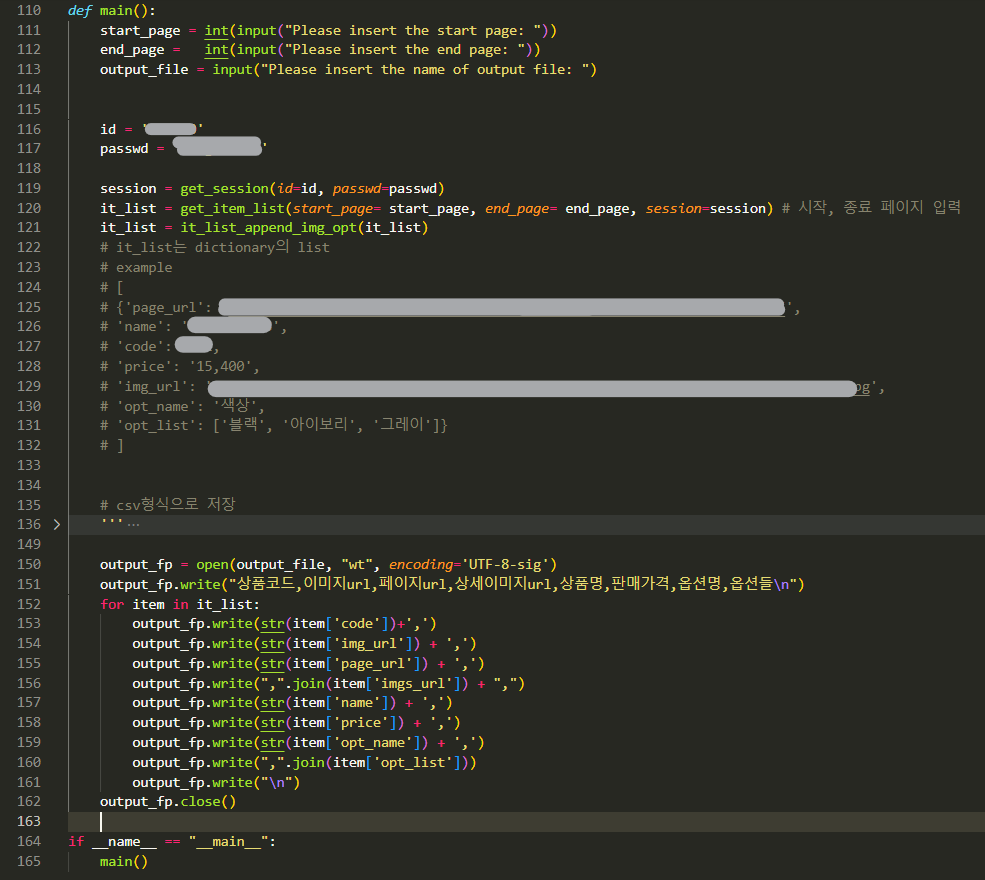
앞서 디자인에서 설명한 것처럼 1단계는 get_session함수를 통해서 로그인세션을 유지하였고, 2단계는 get_item_list함수를 통해서 전체상품페이지에서 데이터를 가져오는 작업을 했습니다. 3단계는 it_list_append_img_opt함수를 통해서 각 상품의 상세페이지에서 가져올 수 있는 상품정보를 가져왔습니다.
이후에 있는 부분은 CSV파일형식으로 저장하기 위해서 작성된 부분입니다.
맨 처음에 start_page, end_page, output_file을 입력해서 크롤링을 시작할 페이지들을 입력하게 하였고, 아웃풋 파일명을 지정할 수 있게 했습니다.
2) get_session 함수
session함수를 구성할 때는 먼저 정상적으로 로그인할때 어떤 과정을 통해서 로그인하는 지 확인해야합니다.
저는 Fiddler를 켜두고 로그인을 한번 해서 어떤 URL을 로그인과정에 거치게 되는지 확인하였고, 이후 이 과정을 동일하게 구현하였습니다.
대상 페이지의 경우에는 로그인을 할 때, 로그인 키세션을 부여하고 그 키세션을 기준으로 다시 로그인 세션정보를 부여했습니다. (이유가 있을텐데, 직관적으로 왜 이렇게 구현했는지 바로 떠오르지는 않네요.id, passwd, sLoginKey가 모두 맞아야 로그인이 될거 같은데 리플레이 공격을 막기위해서 설정해둔거 같아요. 아마도)
그래서 리퀘스트를 보내고, 세션을 저장해서 이후 활용했습니다.
3) get_item_list 함수
위 함수는 특별한 것이 없습니다. 인터넷에서 보면 충분히 찾아볼 수 있는 BeautifulSoup로 페이지 파싱하기와 동일합니다. 전체상품 페이지의 html을 가져와서 필요한 부분을 적절히 파싱하여 가져왔습니다.
4) it_list_append_img_opt 함수
위 함수도 3)과 동일하지만, 한가지 다른점이 있다면 이 부분에 Progress Bar를 반드는 부분을 넣어주었습니다.

다른 함수들과 다르게 이 함수는 for문 안에 Request가 있고, for문의 range값이 크기때문에 Progress바를 만들어줬습니다. (get_item_list함수도 for문 안에 request가 있지만, 이는 range값이 작기에 만들지 않았습니다.)
`\r`를 사용해서 원래 출력된 것을 지워주고, 퍼센테이지로 만드는 방법도 있었으나... 그림으로 만들어주는 것이 더 직관적인거 같아서 위와 같이 했습니다. 그림과 퍼센테이지 모두 보여주는 방법은 굉장히 귀찮기에 하지 않았습니다.

진행중 
위와 같이 바의 길이가 같아지면 완료 5) 완성
실행하고 나면, output file명을 따라서 csv파일이 생성됩니다. 이를 엑셀을 통해서 열면 예쁘게 표로 된 파일이 생깁니다. 사실 굳이 openxl 모듈을 사용하는 것보다는 csv파일로 처리하는 것이 프로그램도 훨씬 가볍고 좋습니다. 물론, 레이어작업 처럼 여러 페이지를 사용해야하는 일이 생기면 관련 API를 사용해야겠지만... csv가 편합니다.
#
- 끝
'Study > Tips' 카테고리의 다른 글
VMware, WSL2가 서로 충돌날 때 해결 방법 (1) 2021.10.18 가상머신 스냅샷을 까먹지 말자... (0) 2021.10.07 MIPS Assembly (0) 2021.10.07 WSL2 포트 포워딩 (2) 2021.09.30 VMWare Bridge Mode 설정하는 법 (223) 2021.09.28 댓글
ugonfor.
보안 위주로 가볍게 작성하였습니다 :)
